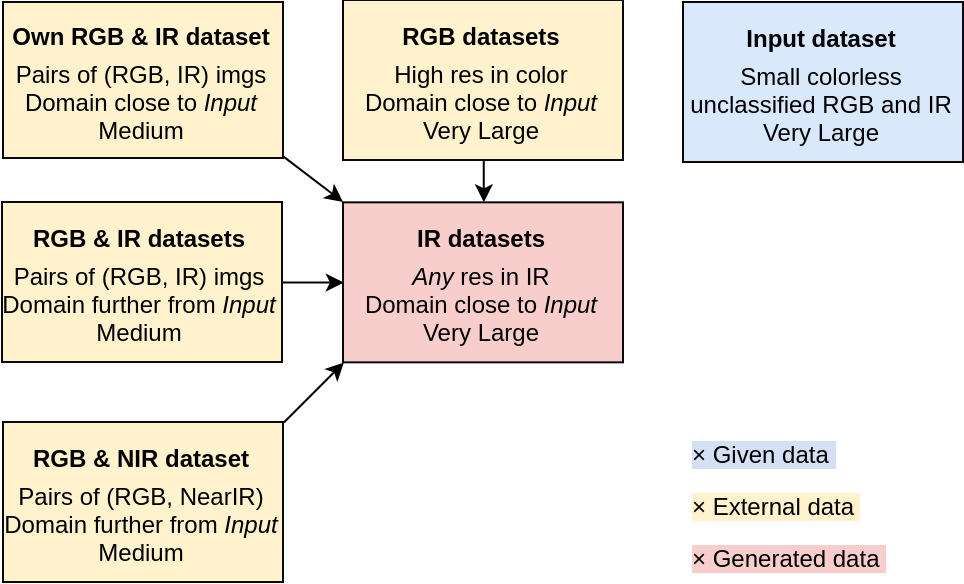
Imagine we have a huge Input dataset of small images from a cheap security cameras. There are several obstacles with images in this dataset:
- Small size (under 200 px × 200 px)
- Grayscale from both visible and infrared spectrum, unsorted
- Partial labels with “meta categories” (human, animal, wind, nothing)
Datasets
To overcome those obstacles, I propose to use the Input dataset only as a validation set (or a part of it to re-train the model). The difference between a deer, a rabbit, a sheep and a snake in comparison to the category “human” is significant enough not to be classified only as an “animal”.
Very large high-res labeled RGB datasets of all needed animals are easy to find: for example Animals with attributes 21 (37322 images of 50 animals), parts of other datasets or a new one using a web scrape.

More challenging is getting a large, high-res labeled IR image dataset. There are plenty of IR datasets, but not in the same domain and for the same purpose as we want. My solution is to use the (RGB, IR) and (RGB, Near IR) pairs datasets to train a conditional GAN (basic idea behind cGANS).



Many more (RGB, IR) and (RGB, NIR) can be found in CVonline: Image Databases. To bring this afford to another level, the best would be to create own (RGB, IR) camera rig and add a small but very similar in domain dataset. This could be done in one day at a trip to a zoo, forests and plains around the city.

Datasets overview
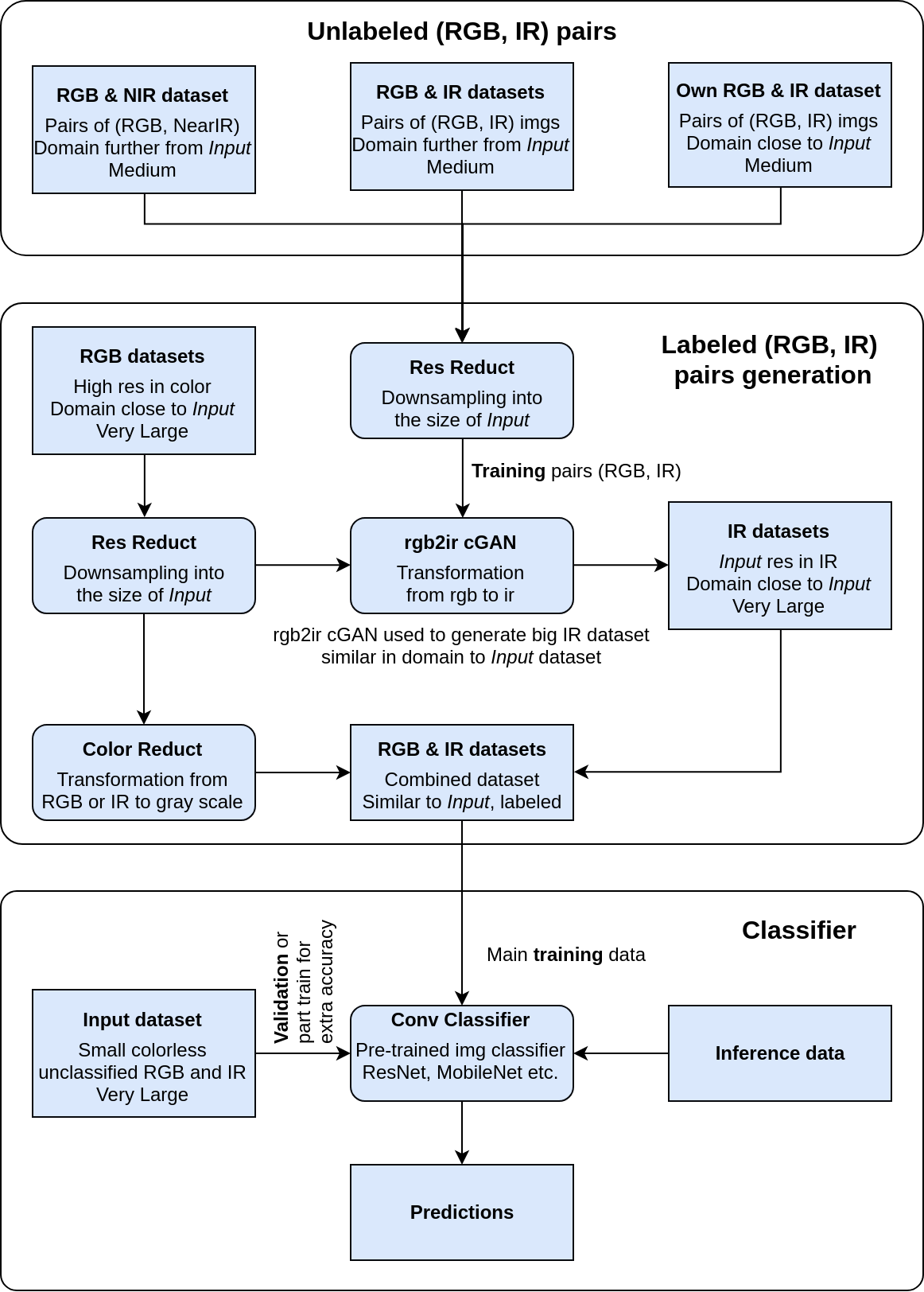
Processing
In proposed models, I will be using following computation blocks:
- Res Reduct – for downsampling
- Color Reduction – for color dim reduction to match Input data
- rgb2ir cGAN – basic Pix2pix2, the same using BigGAN3, or incorporate style AdaIN from StyleGAN4
- Super Resolution – LapSRN5, NVIDIA GAN super res (only a presentation)
- Conv Classifier – ResNet, MobileNet v2 depending on the inference speed needed
Super resolution


Processing overview

Proposed pipelines
The first pipeline is divided into 3 segments. The first is a collection of (RGB, IR) or (RGB, NIR) from different domains used to train second segment. The Labeled (RGB, IR) pair generator is trained on the out-of-domain pairs to generate a large amount of domain-specific IR images with labels (different animals, people, nature). The combined well labeled RGB and IR (or NIR) dataset is used in the classifier to enhance it’s performance.
To improve on models performance I propose to use the high resolution of the well labeled domain-specific images. This would be done by training a super resolution network used to upsample the camera images before classification at inference time. Changes to the first pipeline are colored yellow.
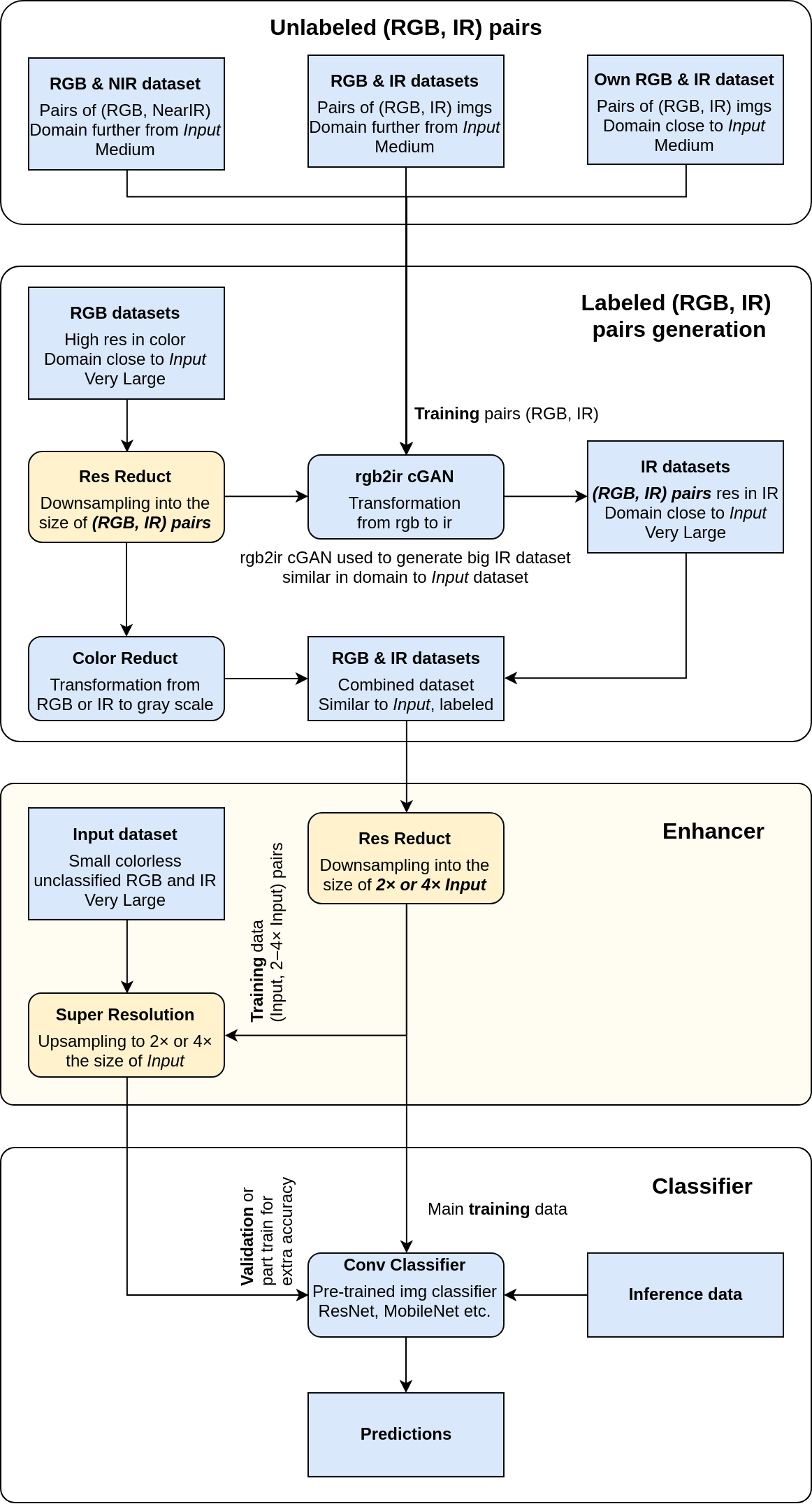
Enhancer could do more than super resolution. Even better, in the time of teaching of the Classifier, merge it with the Enhancer and train both jointly.
Sketches of another approaches
- Build a grayscale RGB/IR classifier and then classify them separately without additional IR images generation
- Skip the Unlabeled (RGB, IR) pairs and the Labeled (RGB, IR) pairs generator segment
- Build the Enhancer for super resolution
- Train the Classifier on only grayscale visible light images with 2–4× res of the Input dataset
- Re-train the Classifier on upscaled Input dataset images
Conclusions
…has yet to be implemented!
References
-
Y. Xian, C. H. Lampert, B. Schiele, Z. Akata. “Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly”, IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI) 40(8), 2018. arXiv:1707.00600 ↩
-
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros. Image-to-Image Translation with Conditional Adversarial Networks. 2016. arXiv:1611.07004 ↩
-
Andrew Brock, Jeff Donahue, Karen Simonyan. Large Scale GAN Training for High Fidelity Natural Image Synthesis. 2018. arXiv:1809.11096 ↩
-
Tero Karras, Samuli Laine, Timo Aila. A Style-Based Generator Architecture for Generative Adversarial Networks. 2018. arXiv:1812.04948 ↩
-
Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, Ming-Hsuan Yang. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. 2017. arXiv:1710.01992 ↩