I used this architecture for deciding whether is a word pronounceable with great results of over 98% accuracy on web scraped evaluation dataset.
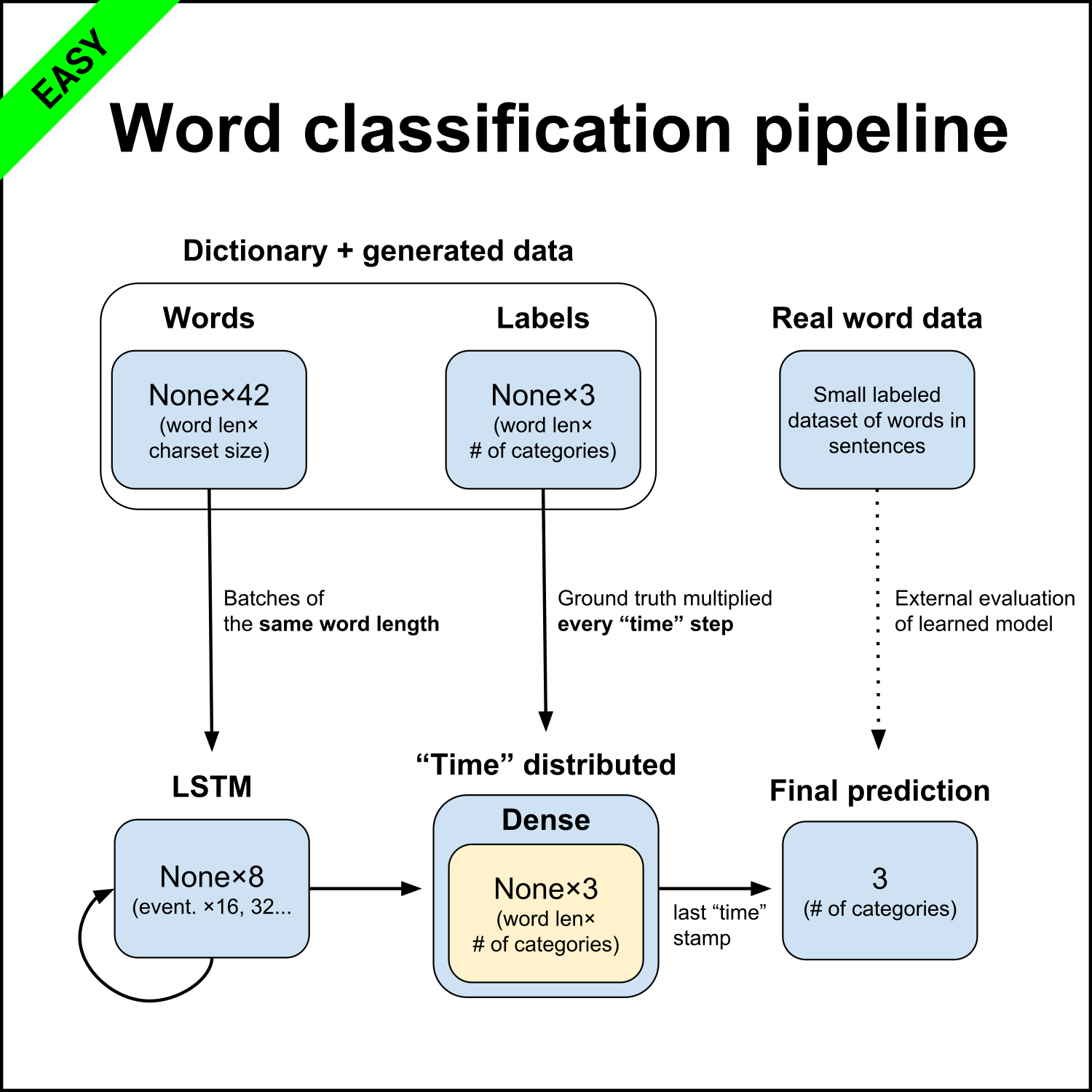
This basic word classification pipeline uses trick of injecting desired category at each “time” stamp. Doing so makes learning quicker and also more accurate on words of length 3+, while only sacrificing meaningful output for solo characters. Padding is avoided by making batches of the same word length.