Assistant senses and capabilities
- Vision
- A standard web camera
- Exposition and other settings are optimized in real-time to enhance the results of face recognition
- Hearing
- A shotgun microphone
- Wide range of STT engines can be used, currently off-line Phonexia
- Voice
- A speaker
- Powered by Google TTS
Face generation
Main goal is to create a realistic video for any sound wave. The generation is split into 2 neural networks to handle the information transformation.
- Sound waves \(\rightarrow\) facial landmarks coordinates
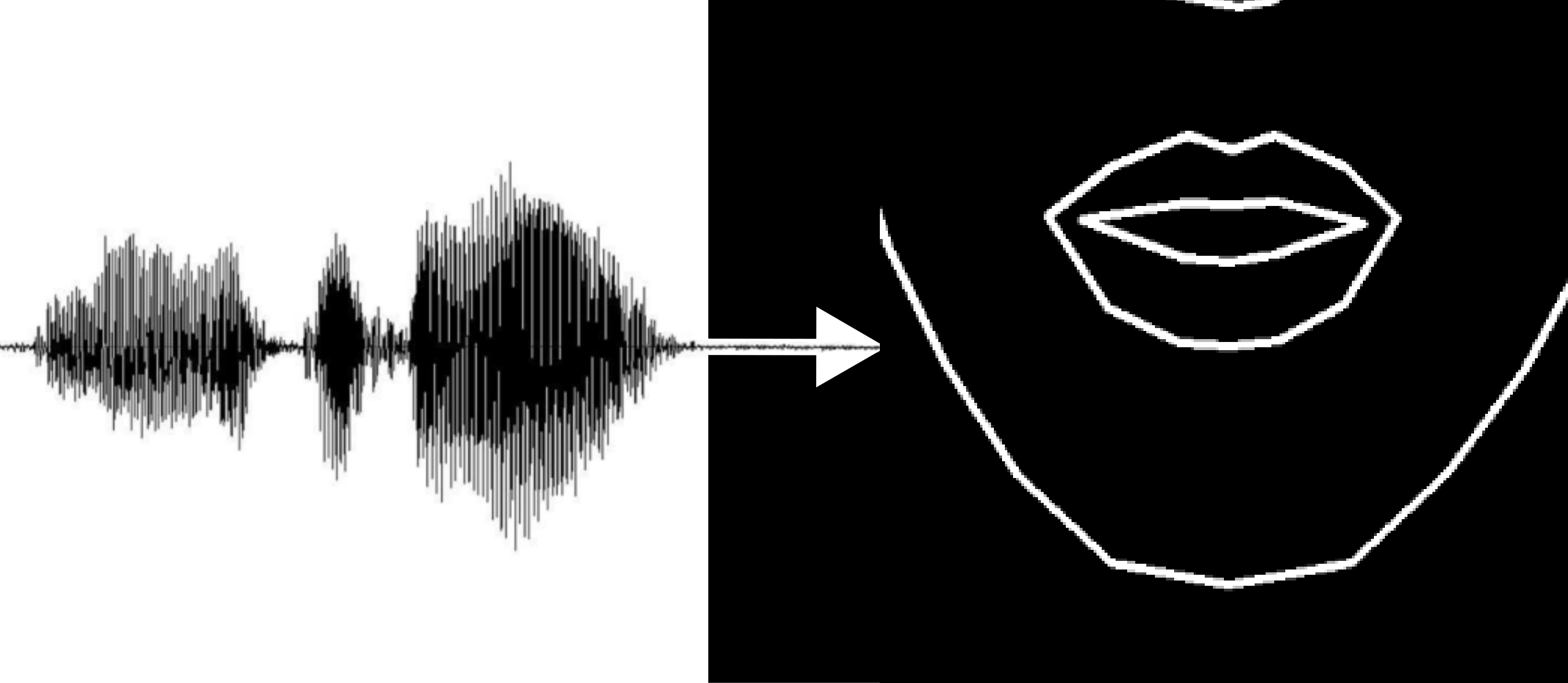
- Drawn landmarks \(\rightarrow\) image of a face
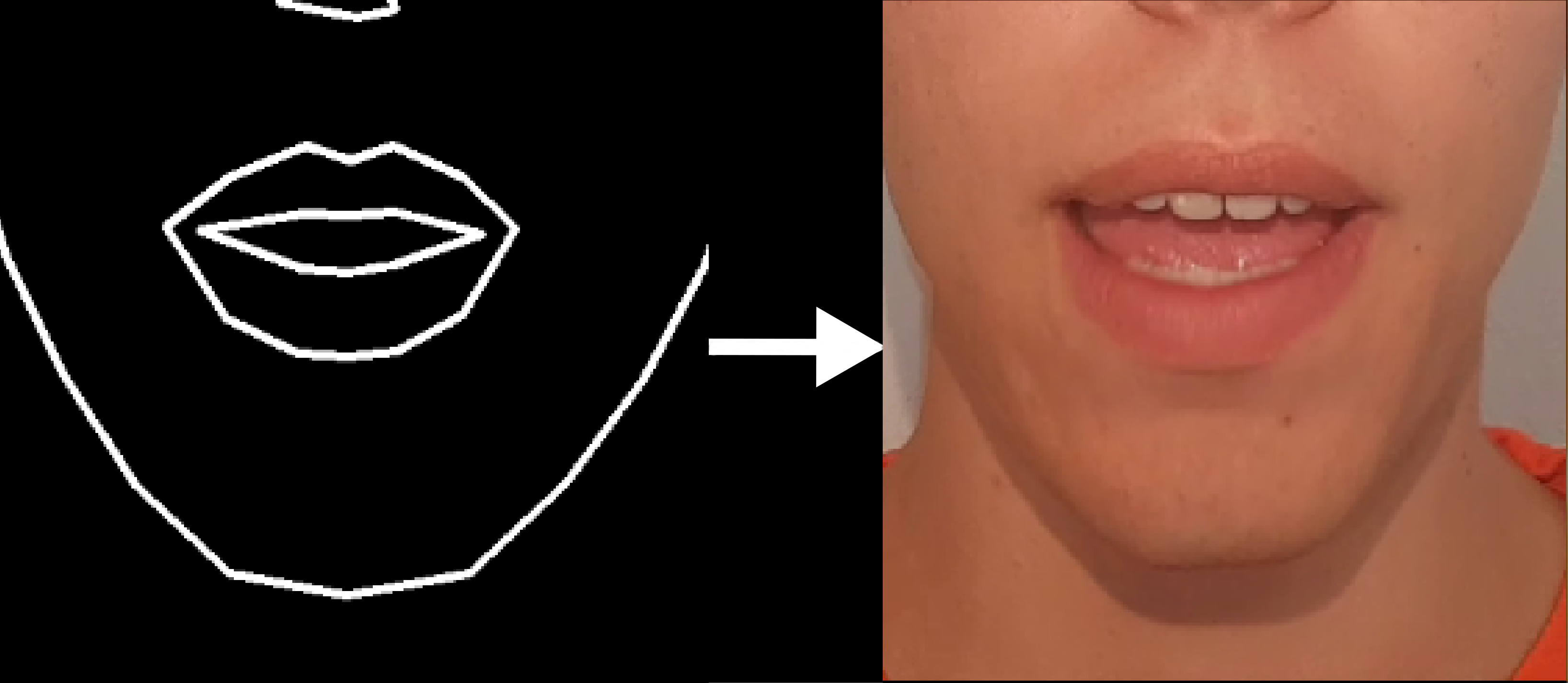
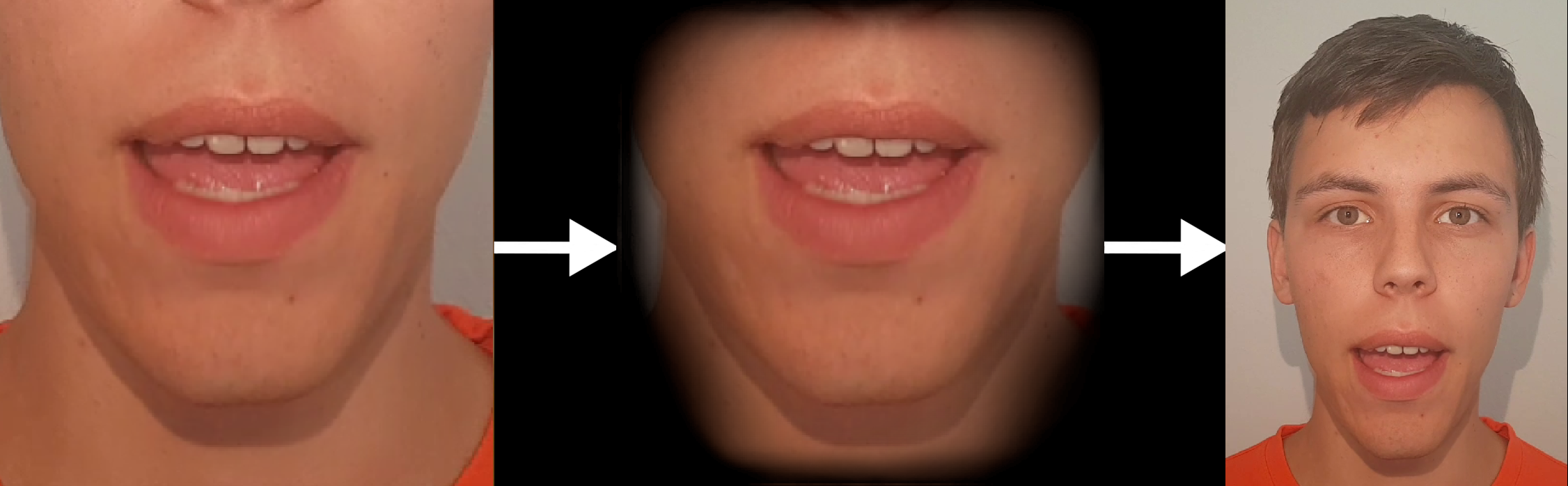
Resulting image of the lower face is then masked and inserted into a real image.
Sound2landmarks
Neural network architecture overview:
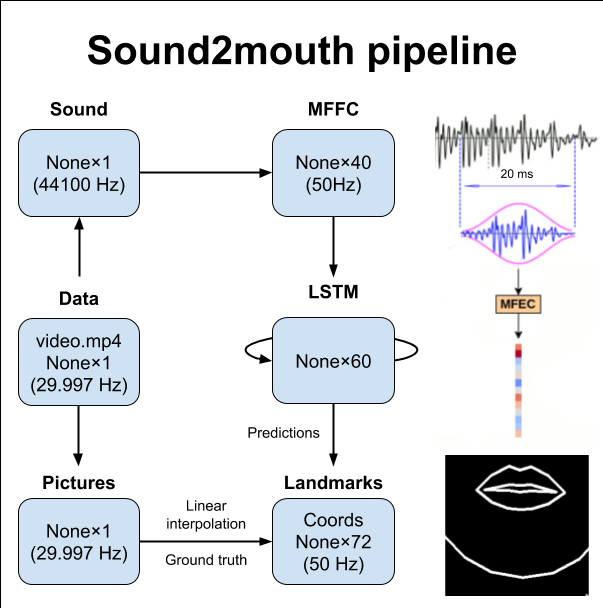
- First try didn’t go so well (the “raw” coordinates are converted to a video)

- It looks like a face, but the network is overfitting and gets into “idle” mode after few seconds.
- How to fix it?
- Coordinates normalization to range [0, 1] ‒ to give the network a range to operate in
- Different lengths of sound‒video sequences ‒ to fight the output idle after few seconds
- Dropout ‒ to fight the overfitting

Landmarks2images
First neural architecture was a conditional GAN with U-net and a landmarks image instead of random variable also known as pix2pix1.
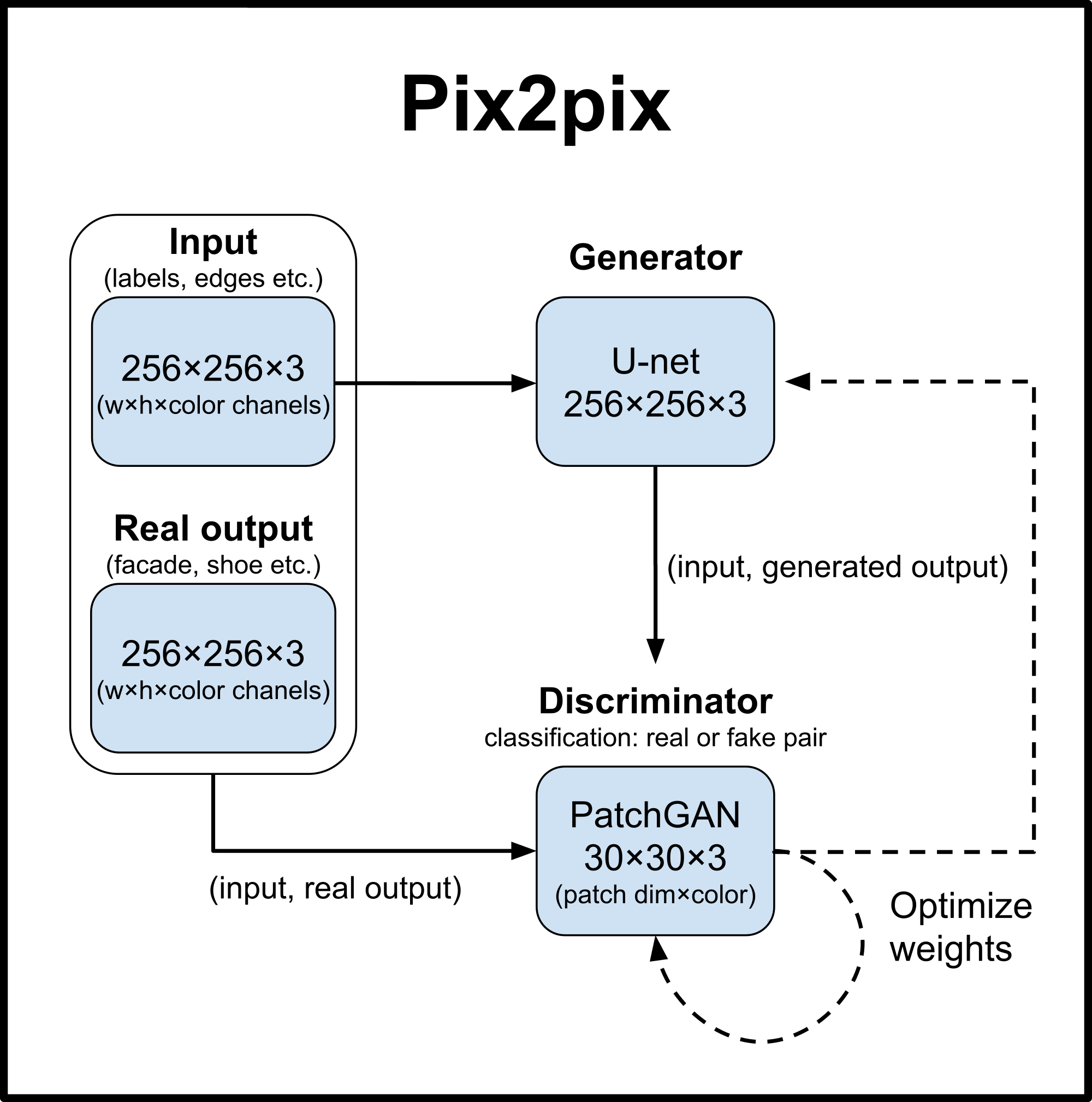

It worked, but because of the used U-net 256×256 px image is the biggest that can be trained on 8 GB of VRAM. Easy workaround is to generate just the mouth and then insert it into an actual video like was done in Obama Lip Sync2. The main advantages are
- Generation of fullHD video
- Easier problem to learn for the cGAN

The mouth looks realistic enough, but there are problems:
- Some frames are corrupted ‒ this is caused mainly by a not optimal lighting conditions
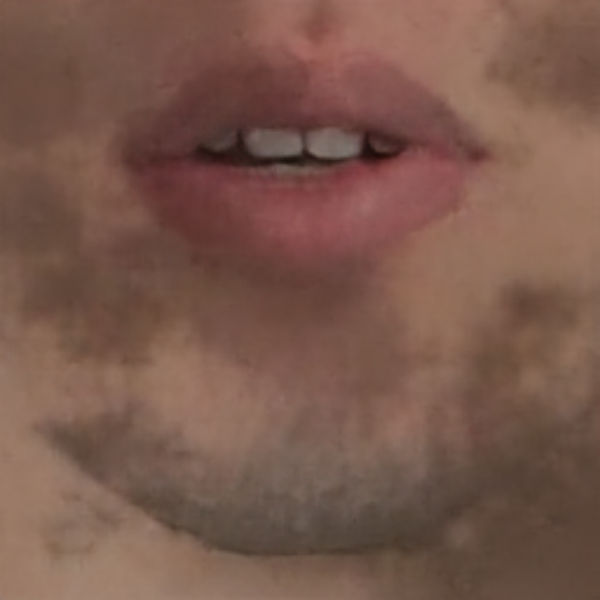
- The absence of time continuity causes flickering that is apparent once inserted into a real video

To solve this, second neural architecture was an updated version of pix2pix from paper Everybody Dance Now3. Generator is looking at the current landmarks frame and the last generated face frame. The Discriminator also works with pairs of landmarks and faces. The source video was changed for a one with better lighting.
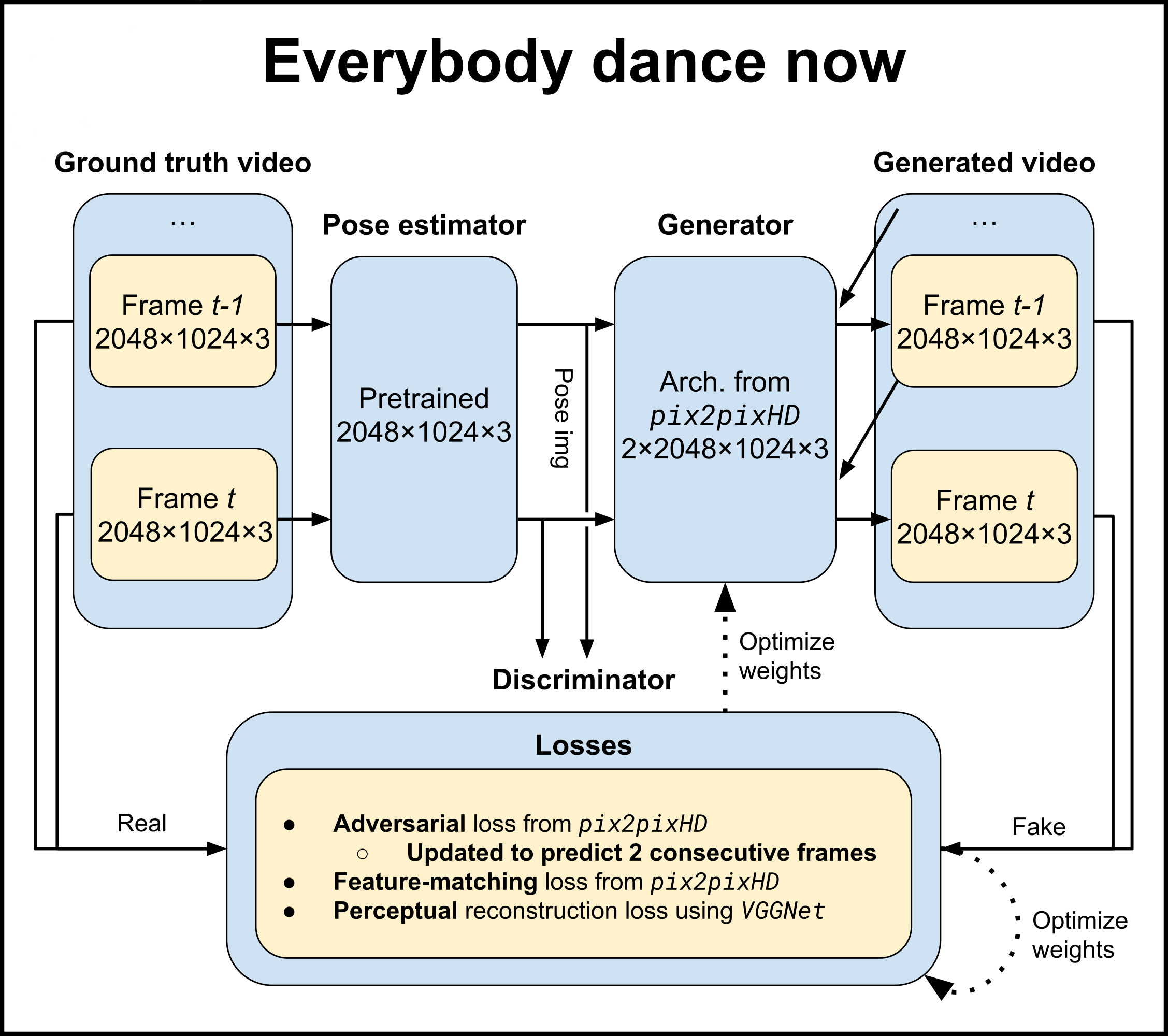
Indeed this approach worked much better than plain pix2pix. For showcase purposes the mouth is placed into still image and normal video.

Conclusion
Overall this neural pipeline is able to create reasonable and arbitrarily long videos of a target person talking given a clear speech sound. Although this setup can produce plausible results, it has limitations:
- At least 1 hour long video of a person talking to the camera
- Lighting without shadows needed
- Jaw misalignment if source video has too much head movement
References
-
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros. 2016. Image-to-Image Translation with Conditional Adversarial Networks. arXiv:1611.07004 ↩
-
Supasorn Suwajanakorn, Steven M. Seitz, Ira Kemelmacher-Shlizerman. 2017. Synthesizing Obama: Learning Lip Sync from Audio. washinton.edu ↩
-
Caroline Chan, Shiry Ginosar, Tinghui Zhou, Alexei A. Efros. 2018. Everybody Dance Now. arXiv:1808.07371 ↩