MobileNet v21 is state-of-the-art in precision for models targeted for real-time processing. It doesn’t reach the FPS of Yolo v2/v3 (Yolo is 2–4 times faster, depending on implementation). That said let’s think about some upgrades that would make a MobileNet v3.
Upgrade the dataset
DNNs are often held back by the dataset, not by the model itself. The creation (and annotation) of real datasets with high diversity is hard and costly. The proposed idea from NVIDIA is to pretrain the model with synthetic data2.
This has been done before, but NVIDIA examines the effects of randomization beyond the test set domain. The added diversity in pretrain phase increases the performance by a significant margin especially for the SSD.
Results for KITTI validation set pretrained on Virtual KITTI or NVIDIA synthetic data:
| Architecture | Virtual KITTI | NVIDIA |
|---|---|---|
| Faster R-CNN | 79.7 | 78.1 |
| R-FCN | 64.6 | 71.5 |
| SSD | 36.1 | 46.3 |
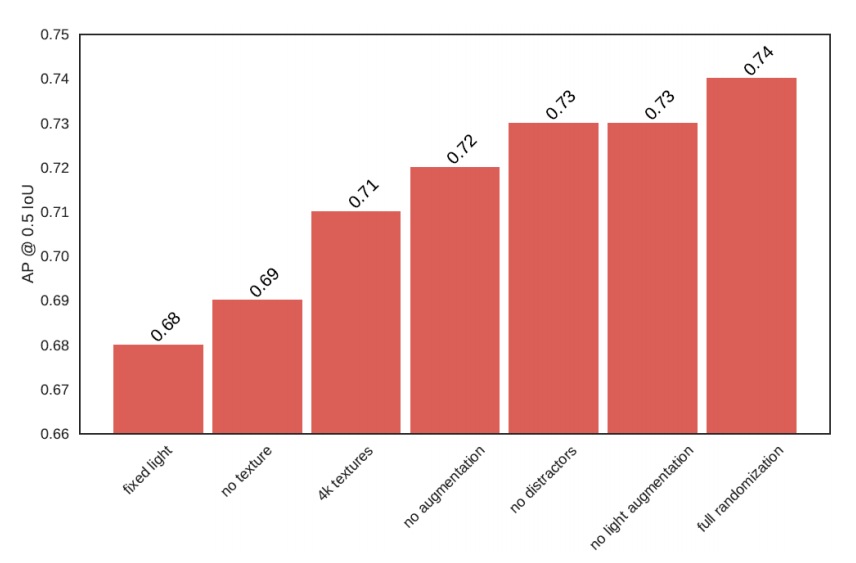
As shown in the chart below, unrealistic textures and different lighting conditions have the most significant impact.
Examples of synthetic scenes:


On the cars in KITTI dataset the Avg. Precision @ .50 IoU increases from 96.5 to 98.5 in other words the average error is reduced by 57 % by the usage of synthetic data + 6000 real images.
Faster multi-scaling
In the original paper introducing MobileNetV23 including multi-scale inputs and adding leftright flipped images (MF) and decreasing the output stride (OS) increases the mean IoU from 75.32 % to 77.33 %. Adding Atrous Spatial Pyramid Pooling (ASPP) increases it further to 78.42 %. The researchers argue not to include due to the almost 100× increase in the multiply-accumulate operations (MAdds).
Results for PASCAL VOC 2012 validation set:
| OS | ASPP | MF | mIoU | MAdds |
|---|---|---|---|---|
| 16 | 75.32 | 2.75B | ||
| 8 | ✓ | 77.33 | 152.6B | |
| 8 | ✓ | ✓ | 78.42 | 387B |
To harnest the advantages of multi-scale processing while keeping the MAdds low I propose to incorporate the recently published TridentNet architecture4. It works by proposing independent predictions for different sizes of objects.
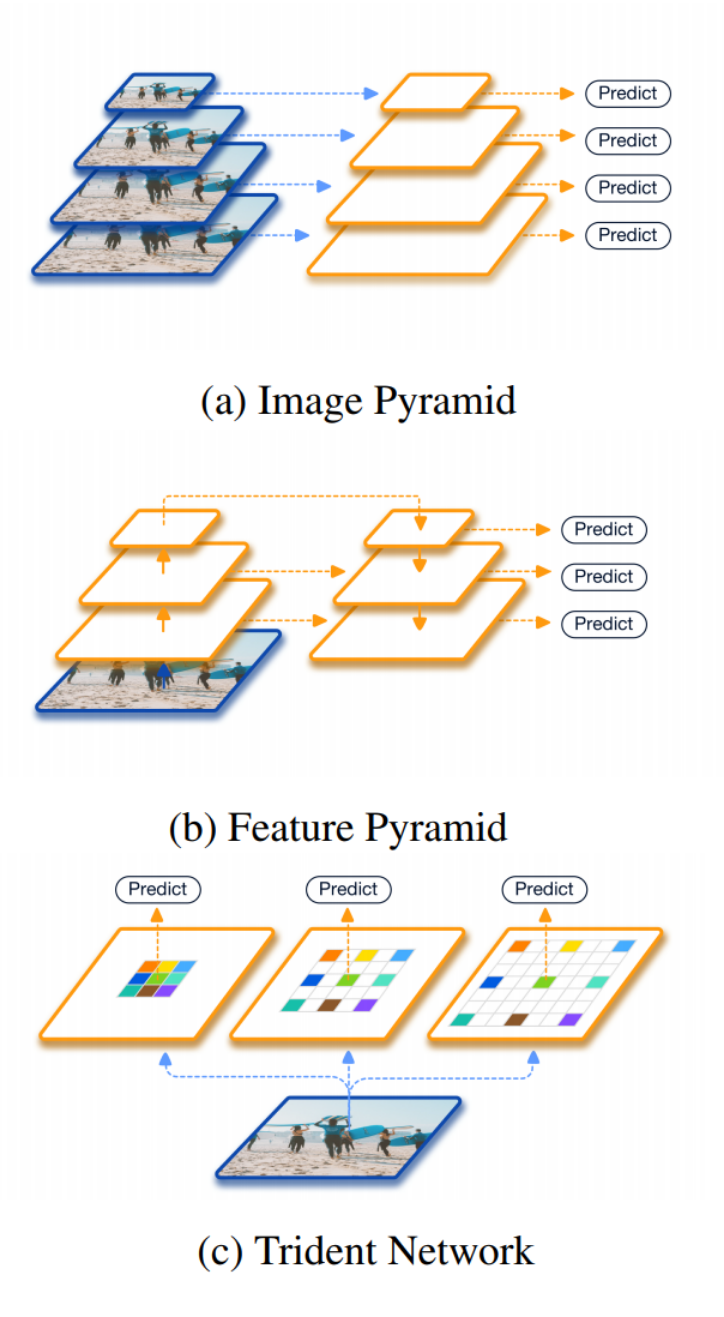
Results for COCO test-dev set:
| Method | Backbone | AP | AP @ 0.5 | AP small | AP medium | AP large |
|---|---|---|---|---|---|---|
| SSD513 | ResNet-101 | 31.2 | 50.4 | 10.2 | 34.5 | 49.8 |
| Deformable R-FCN | Aligned-Inception-ResNet-Deformable | 37.5 | 58.0 | 19.4 | 40.1 | 52.5 |
| SNIPER | ResNet-101-Deformable | 46.1 | 67.0 | 29.6 | 48.9 | 58.1 |
| TridentNet | ResNet-101 | 42.7 | 63.6 | 23.9 | 46.6 | 56.6 |
| TridentNet* | ResNet-101-Deformable | 48.4 | 69.7 | 31.8 | 51.3 | 60.3 |
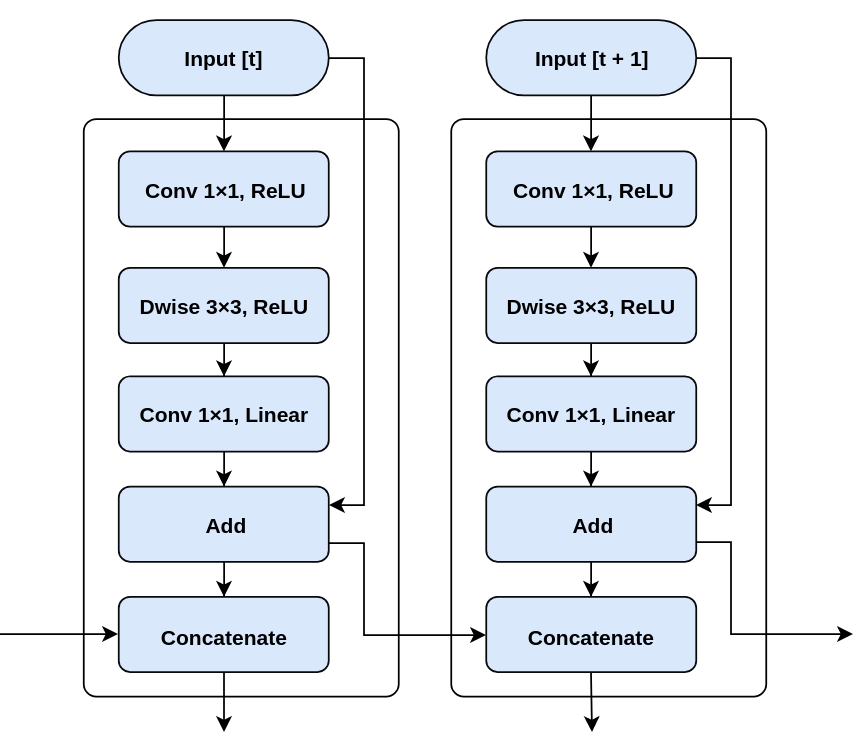
Time coherent predictions
The first shot on minimizing the frame-to-frame inconsistency – the idea is inserting the information from last frame into the new frame processing. If the insertion is done at the linear bottlenecked layer, the added processing complexity for merging is minor in comparison to the convolutional layers.

Conclusions
By implementing 3 higher outlined improvements to the dataset and the architecture, there is a theoretical potential for improvement of AP between 4 and 15 % depending on the task. Introduction of time coherence can reduce the prediction flickering and thus increase the ease of further use.
References
-
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. 2018. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv:1801.04381 ↩
-
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, Stan Birchfield. 2018. Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization. arXiv:1804.0651 ↩
-
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen. 2018. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv:1801.04381 ↩
-
Yanghao Li, Yuntao Chen, Naiyan Wang, Zhaoxiang Zhang. 2019. Scale-Aware Trident Networks for Object Detection. arXiv:1901.01892 ↩